.svg)
.svg)
What 94.7% severity classification accuracy actually measures

Most AI testing tools claim high accuracy rates. Few explain what they're measuring.
The accuracy problem nobody defines
Every vendor touts 90%+ accuracy. But accuracy of what?
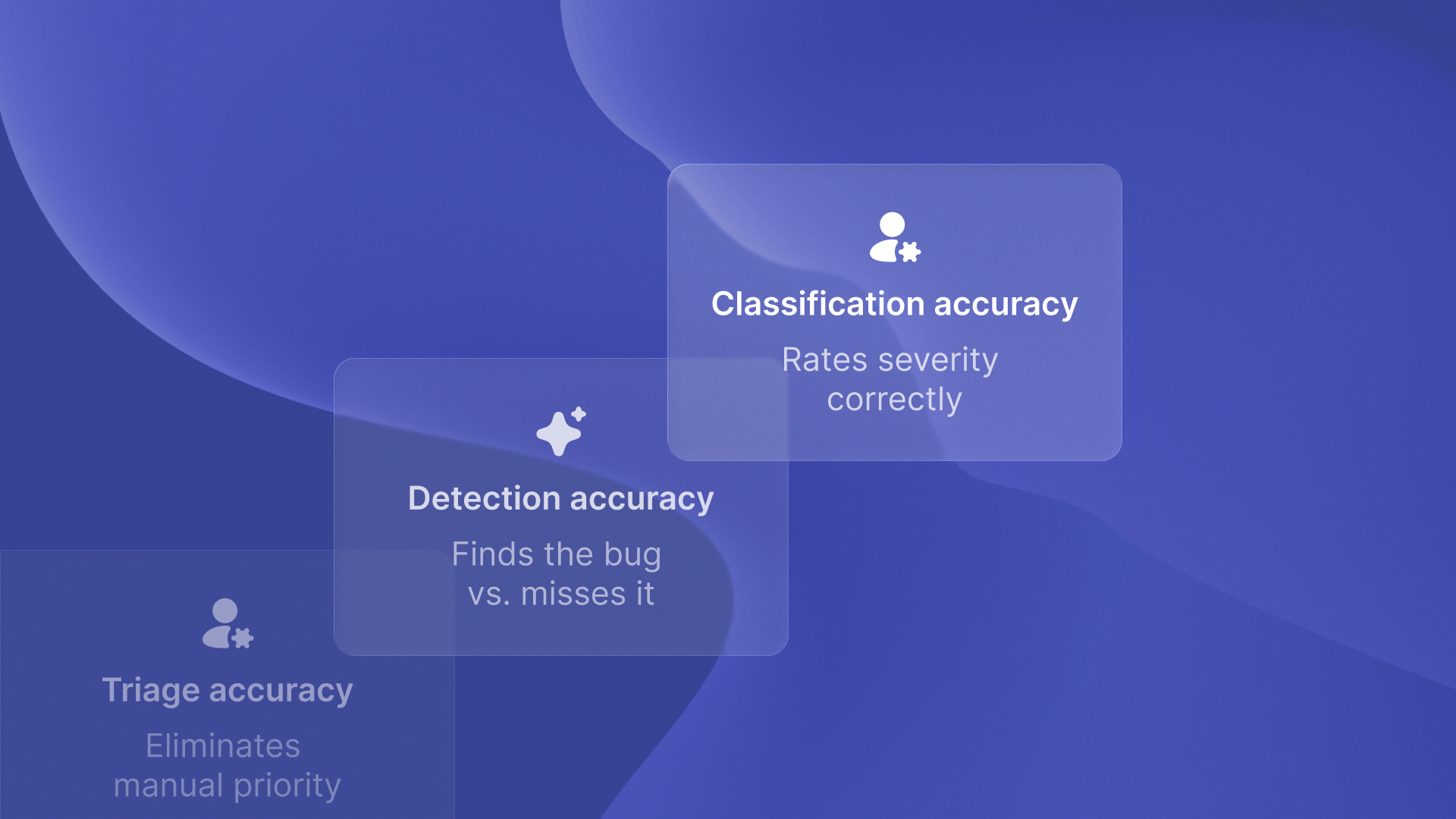
Detection rates measure whether the system finds bugs versus missing them. Classification accuracy measures whether severity ratings match human expert judgment. Triage automation measures whether the system eliminates manual prioritization work.
These are fundamentally different capabilities. AI bug detection achieves up to 93% accuracy across datasets. That number tells you nothing about whether bugs are classified correctly. It also doesn’t show if your team wastes less time debating priority.
QA flow reaches 94.7% severity classification accuracy. That's a specific, measurable claim about a concrete problem: eliminating QA-developer prioritization debates.
What severity classification actually means
Traditional manual severity classification relies on subjective judgment. QA files a bug as P1. Engineering disagrees and downgrades it to P2. Three Slack messages and a Zoom call later, they settle on P1 after all.
This overhead compounds across hundreds of bugs per sprint. Without network logs, error patterns, and impact data, severity becomes opinion-based rather than data-driven.
ML models classify severity differently. They analyze HTTP response codes, failed API endpoints, console errors, rendering failures, and affected user workflows. This is fundamentally different from a human guessing based on incomplete information.
How the model works
QA flow's multi-agent system processes four input categories:
Network logs: Which API endpoints returned errors? What were the response codes? How many requests failed?
Error patterns: What JavaScript errors appeared in the console? Which rendering failures occurred? What timeout issues surfaced?
User impact signals: Which workflows broke completely? Which features degraded but remained functional? How many users hit the broken path?
Stack traces: Where did the failure originate in the codebase? Which components were affected?
The model weights these inputs against patterns from thousands of classified bugs. When a new bug arrives, the system compares its signature against known severity patterns.
94.7% of the time, the severity rating matches what an experienced engineering team would assign after full investigation.
Why this eliminates debates
Machine learning bug triage reduces developer effort by 35%. That number represents time saved arguing about which bugs to fix first.

When bugs include network logs, engineers do not argue about priorities. The logs show broken endpoints. They also include severity ratings backed by data.
When bugs come with network logs, engineers act fast. The logs show broken endpoints. They also include severity ratings based on data. Engineers do not waste time debating what to fix first. The context is complete before the ticket reaches them.
A P1 bug report comes in. The failed API endpoint is logged. The exact HTTP 500 error is captured. The broken user workflow is documented. A video showing how to reproduce the issue is attached. There's nothing to debate. The investigation already happened automatically.
This is production-ready context, not a QA observation that "the checkout button doesn't work sometimes."
The methodology behind 94.7%
The accuracy metric shows how often ML labels match expert human labels. This is based on a validation set of 2,400 bugs. Each bug in the validation set received severity ratings from three senior engineers independently.
The model's classification matched the consensus expert rating 94.7% of the time.
This isn't abstract machine learning performance. It measures how often the system removes the need for human severity talks. It does this because it already reached the same conclusion as the team.
The remaining 5.3% aren't errors. They are edge cases where even skilled engineers disagree on severity. Business context the model cannot access may override technical severity.
The takeaway
Severity classification isn't about replacing human judgment. It's about eliminating the debates that waste it.
When bugs include network logs, teams can see which endpoints are broken. The logs also show clear severity ratings. Teams do not argue about priority. They spend that time fixing issues.
QA flow's 94.7% accuracy doesn't mean the system is right 94.7% of the time in some abstract sense. It means 94.7% of its severity classifications match what an experienced engineering team would assign after full investigation.
The investigation already happened automatically. The debates end before they start.
.png)
.png)

